Oct 2023 Tweet
Mechanistic interpretability of LLM analogy-making
Can LLM make analogies? Yes, according to tests done by Melanie Mitchell a few years back, GPT-3 is quite decent at “Copycat” letter-string analogy-making problems. Copycat was invented by Douglas Hofstadter in the 80s, to be a very simple “microworld”, that would capture some key aspects of human analogy reasoning. An example of a Copycat problem:
”If the string abc changes to the string abd, what does the string pqr change to?“
Many more examples are collected on this page.
A project that I'm working on while studying mechanistic interpretability (MI), is applying MI to an LLM's ability to solve Copycat problems.
According to Douglas Hofstadter, analogy is the core of cognition [1], and it can be argued that it is a basis for various abstract reasoning abilities. There are other similar problem domains that require few-shot abstract reasoning — like inductive program synthesis, abstraction and reasoning challenge, etc… Still, Copycat is the simplest one, which makes it a good starting point for MI.
selecting a model & test prompts
It would be nice to use GPT-2 for the investigation, a lot of recent work in MI has been done based on it. But, alas, it does not seem to be able to solve analogy puzzles.
I have chosen Llama-7B-chat — it’s able to solve Copycat-like problems, and is small enough to be convenient for experimentation. It does not work as well as GPT-3.5 for Copycat and I had to tweak the problem formulation, but, eventually, I got it to solve simplified problems like:
- prompt: "0 1 2 to 2 1 0, 1 2 3 to 3 2 1, 4 5 6 to ", output: “6 5 4”
- prompt: "0 1 2 to 0 1 3, 1 2 3 to 1 2 4, 4 5 6 to ", outuput: “4 5 7”
- prompt: “0 1 to 0 1 1, 1 2 to 1 2 2, 4 5 to “, output: “4 5 5”
Llama-7B has a fairly "standard" transformer architecture with 32 blocks and 32 attention heads in each block.
logit lens
I have started with applying logit lens [3] to the first test prompt:
"0 1 2 to 2 1 0, 1 2 3 to 3 2 1, 4 5 6 to "
Logit lens output for this prompt is shown below: top 5 tokens with probabilities, predicted for for the last token in the prompt, for all 32 blocks of Llama-7b-chat. It's supposed to predict "6", the first token of the correct solution:
0: пута 0,076 | penas 0,015 | sier 0,011 | сылки 0,009 | partiellement 0,009 |
1: rep 0,006 | accomp 0,006 | soft 0,005 | regular 0,005 | use 0,004 |
2: rep 0,016 | accomp 0,010 | M 0,007 | gex 0,004 | use 0,004 |
3: pec 0,021 | 间 0,009 | gepublic 0,009 | wat 0,007 | opp 0,007 |
4: pec 0,039 | Пе 0,015 | ynt 0,006 | util 0,006 | voc 0,005 |
5: pec 0,017 | ynt 0,014 | oro 0,006 | igt 0,006 | mn 0,005 |
6: oth 0,015 | conde 0,008 | arz 0,008 | ynt 0,008 | со 0,008 |
7: со 0,015 | patch 0,007 | lex 0,005 | oth 0,005 | Mand 0,005 |
8: gate 0,020 | Bru 0,009 | lea 0,007 | lear 0,007 | mers 0,006 |
9: со 0,020 | 宿 0,009 | anim 0,008 | nelle 0,007 | ❯ 0,007 |
10: iente 0,012 | ❯ 0,012 | Pas 0,011 | ole 0,007 | lear 0,006 |
11: ole 0,032 | iente 0,018 | ще 0,011 | reen 0,007 | colo 0,007 |
12: ole 0,012 | Glen 0,011 | pas 0,006 | sono 0,006 | lex 0,006 |
13: vert 0,017 | 忠 0,012 | vice 0,012 | Vert 0,008 | bage 0,007 |
14: mul 0,023 | Mul 0,014 | sono 0,010 | tie 0,008 | vice 0,006 |
15: sono 0,019 | Mul 0,014 | Pas 0,011 | vice 0,008 | tie 0,006 |
16: sono 0,014 | tring 0,014 | 6 0,012 | kwiet 0,008 | aug 0,007 |
17: 6 0,744 | six 0,115 | Six 0,059 | sixth 0,017 | 六 0,009 |
18: 6 0,715 | six 0,164 | Six 0,049 | sixth 0,009 | 六 0,003 |
19: 6 0,852 | six 0,097 | Six 0,010 | sixth 0,007 | seis 0,003 |
20: 6 0,920 | six 0,034 | Six 0,007 | sixth 0,007 | 5 0,006 |
21: 6 0,884 | six 0,042 | 5 0,009 | sixth 0,007 | Six 0,006 |
22: 6 0,843 | six 0,037 | 5 0,014 | sixth 0,008 | Six 0,008 |
23: 6 0,848 | six 0,030 | 5 0,015 | sixth 0,004 | Six 0,003 |
24: 6 0,837 | 5 0,024 | six 0,014 | 3 0,005 | sixth 0,003 |
25: 6 0,932 | six 0,029 | sixth 0,006 | Six 0,005 | 5 0,002 |
26: 6 0,934 | six 0,023 | 5 0,004 | sixth 0,004 | Six 0,003 |
27: 6 0,956 | six 0,013 | 5 0,007 | sixth 0,002 | 3 0,002 |
28: 6 0,980 | 5 0,009 | 3 0,003 | six 0,002 | 2 0,001 |
29: 6 0,982 | 5 0,012 | 3 0,001 | six 0,001 | 2 0,000 |
30: 6 0,985 | 5 0,013 | 3 0,001 | 2 0,000 | 7 0,000 |
31: 6 0,960 | 5 0,029 | 3 0,005 | 7 0,002 | 2 0,002 |
“6” (correct prediction), appears in block #16, and is then amplified in the next blocks. To narrow down the analysis, I’ll initially focus on block #16.
zero ablation
To figure out where “6” output comes from, first I’ve zeroed MLP output in block #16. This did not change the result much:
14: mul 0,023 | Mul 0,014 | sono 0,010 | tie 0,008 | vice 0,006 |
15: sono 0,019 | Mul 0,014 | Pas 0,011 | vice 0,008 | tie 0,006 |
16: sono 0,015 | 6 0,013 | vice 0,009 | tring 0,008 | kwiet 0,008 |
17: 6 0,770 | six 0,085 | Six 0,054 | sixth 0,022 | 六 0,007 |
18: 6 0,817 | six 0,074 | Six 0,036 | sixth 0,010 | 5 0,004 |
19: 6 0,906 | six 0,041 | sixth 0,007 | 5 0,005 | Six 0,004 |
20: 6 0,934 | six 0,016 | 5 0,009 | sixth 0,006 | Six 0,003 |
Next, I’ve tried to find attention heads that are responsible for the output — zero ablating attention heads (one at a time). The following image shows the probability of “6” token prediction for test with zeroing each of the 32 attention heads in block #16:
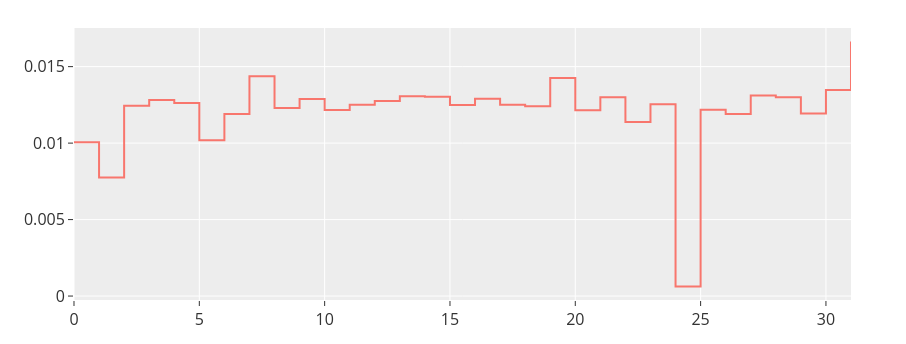
Head #24 is an outlier, and my guess is that it is responsible for copying “6” into the correct position.
Here is how this attention head’s weights look:

Indeed, attention for the last token which should predict “6” (bottom row), is focused on the 3rd token from the end, which is “6” in the input (bright pixel close to the bottom right corner)
next steps
This has been a small fraction the required analysis, and the approach has been quite naive. But at this point I have exhausted my knowledge of interpretability methods, which only include logit lens and zero ablation. I’ll continue trying to find the circuit responsible for solving test prompts, just need to learn more of MI.
references
- Analogy as the Core of Cognition by Douglas R. Hofstadter
- Moskvichev, Arseny et al. “The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain.” ArXiv abs/2305.07141 (2023): n. pag.
- interpreting GPT: the logit lens
- Li, Maximilian et al. “Circuit Breaking: Removing Model Behaviors with Targeted Ablation.” ArXiv abs/2309.05973 (2023): n. pag.