Dec 2023
Llama.MIA — fork of Llama.cpp with interpretability features
I have been using llama.cpp for learning about transformers and experimenting with LLM visualizations and mechanistic interpretability.
Initially I’ve just inserted bunch of code all over the ggml compute framework. That code was not thread safe, used lots of hardcoded values, and communicated using global variables.
Now I have refactored it a bit, moving most of the code into hooks/callbacks. New version is called Llama.MIA, where MIA stands for “mechanistic interpretability application”. For now, only CPU version is supported, and it has been tested only with Llama2.
Next sections describe building, setup and usage.
Setup
# get the code, checkout the branch
git clone https://github.com/coolvision/llama.mia
cd llama.mia
git checkout mia
# build
make mia
# obtain the original LLaMA2 model weights and place them in ./models
ls ./models
ggml-vocab-llama.gguf llama-2-7b llama-2-7b-chat llama.sh tokenizer_checklist.chk tokenizer.model
# install Python dependencies
python3 -m pip install -r requirements.txt
# convert to ggml FP16 format
python3 convert.py models/llama-2-7b-chat/
# quantize the model to 4-bits (using q4_0 method)
./quantize ./models/llama-2-7b-chat/ggml-model-f16.gguf ./models/llama-2-7b-chat/ggml-model-q4_0.gguf q4_0
# run the inference
ln -s ./models/llama-2-7b-chat/ggml-model-q4_0.gguf llama2.gguf
./mia -m llama2.gguf -n 128Attention map visualization
--draw PATH, for example:
./mia -m llama2.gguf --prompt "William Shakespeare was born in the year" -n 5 --draw ~/tmp/llama_vis.png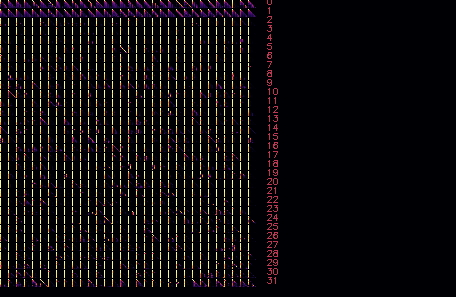
Computation graph printout
--print-cgraph — first prints the details of all the tensors:
./mia -m llama2.gguf --print-cgraph
TYPE OP NDIMS NE0 NE1 NE2 NE3 NB0 NB1 NB2 NB3 DATA NAME
q4_0 NONE 2 4096 4096 1 1 18 2304 9437184 9437184 0x7fb20e57ae40 blk.0.attn_k.weight
q4_0 NONE 2 4096 32000 1 1 18 2304 73728000 73728000 0x7fb202f9ce40 token_embd.weight
i32 NONE 1 1 1 1 1 4 4 4 0x7fb1ee52e020 inp_tokens
f32 NONE 1 4096 1 1 1 4 16384 16384 16384 0x7fb21490ae40 blk.0.attn_norm.weight
[...]
Next, all the nodes in the computation graph
ARG TYPE OP NDIMS NE0 NE1 NE2 NE3 NB0 NB1 NB2 NB3 DATA NAME
DST f32 GET_ROWS 1 4096 1 1 1 4 16384 16384 16384 0x7fb1ee52e040 inp_embd
SRC q4_0 NONE 2 4096 32000 1 1 18 2304 73728000 73728000 0x7fb202f9ce40 token_embd.weight
SRC i32 NONE 1 1 1 1 1 4 4 4 4 0x7fb1ee52e020 inp_tokens
DST f32 RMS_NORM 1 4096 1 1 1 4 16384 16384 16384 (nil) norm-0
SRC f32 GET_ROWS 1 4096 1 1 1 4 16384 16384 16384 0x7fb1ee52e040 inp_embd
[...]
Logit lens
Internally, transformers use representations that are encoded in the embedding space. To convert a transformer's output into meaningful tokens, it's multiplied with the unembedding matrix.
The idea of the logit lens, is to apply the same transformation to intermediate layers, allowing to interpret transformer's hidden internal state.
--ll TENSOR_NAME TOP_K, --logit-lens TENSOR_NAME TOP_K — prints TOP_K un-embedded tokens for a specified tensor. Partial matches of the tensor names work as well, so if TENSOR_NAME is “l_out” it will print logit lens results for all layers (“l_out-0”, “l_out-1”, …). “l_out-20” will print if only for layer 20.
It will work for the tensors of the residual stream (l_out), as well as for attention outputs (kqv_out), MLP outputs (ffn_out), and other tensors with the embedding dimensions.
./mia -m llama2.gguf --prompt "The capital of Japan is" -n 5 --ll l_out 8
unembed LN 0 l_out-0:
0: Архив 1.3|bolds 1.3|archivi 1.1| konn 1.1|penas 1.1| partiellement 1.1|пута 1|embros 0.97|
1: пута 0.51| sier 0.42| Censo 0.38| Архив 0.37| virtuel 0.37|penas 0.36|Portail 0.36|férences 0.33|
2: férences 0.18| straight 0.18|empre 0.17| Censo 0.17| succ 0.17|寺 0.17| soft 0.17|csol 0.17|
3: пута 0.44| partiellement 0.33|archivi 0.29| sier 0.28| cí 0.28|Sito 0.28| konn 0.28|embros 0.25|
4: archivi 0.25|➖ 0.25|пута 0.25| returns 0.23|瀬 0.23|textt 0.22|Sito 0.21|ѐ 0.21|
5: 昌 0.17|ic 0.16| Tro 0.15| solution 0.15| first 0.14|icked 0.14| ic 0.14|opera 0.14|
6: пута 0.28|nt 0.26|archivi 0.24|embros 0.21| sier 0.21|Sito 0.21|阳 0.21| also 0.2|
[...]
unembed LN 18 l_out-18:
0: Unterscheidung 1.1e+02| Hinweis 1.1e+02| nobody 1e+02| sierp 1e+02| everybody 1e+02| Einzeln 98| kwiet 97| Begriffe 95|
1: 6.9|penas 6.2| following 5.6|odor 5.5| článku 5| purpose 4.7|Ḩ 4.6| Following 4.6|
2: ization 7.5|ist 6.5| pun 6.4|isation 6| city 5.7|ized 5.7| letters 5.6|ists 5.2|
3: France 4.5|flow 4.4| flows 3.9| Germany 3.8| Australia 3.7| United 3.6|imo 3.5| Italy 3.5|
4: ped 3.3|amb 3|ira 3|ade 2.9| conserv 2.8|ung 2.8|ew 2.8| pied 2.7|
5: ese 6.3|eses 4.7| Une 4|esen 3.9|imation 3.5|fen 3.5|amer 3.4| abbre 3.3|
6: capital 6.3| Tokyo 5.3| Capital 4.9| capit 4.8| called 4.3| city 4.3| cities 4.2| Hinweis 3.9|
Attention head zero-ablation
Zeroing the output of an attention head is useful for verifying if it is responsible for a certain beahvoir. For example, "Mechanistically interpreting time in GPT-2 small"
-a INDEXES, --ablate INDEXES — zero ablate attention heads with indexes from a comma-separated list
./mia -m llama2.gguf --prompt "William Shakespeare was born in the year" -n 5 --ablate 0,1,2,3,4,5,6,7,8,48,49,50,60,175,180,190,200 --draw ~/tmp/llama_vis_a.pngEffect of the ablation can be inspected on the visualized attention maps.
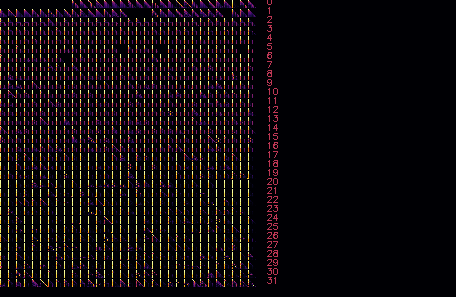
-s LAYER INDEX, --select LAYER INDEX — for a specific layer, zero all attention heads except for one with specified index. For example, leave only one head on L16:
./mia -m llama2.gguf --prompt "William Shakespeare was born in the year" -n 5 --select 16 24 --draw ~/tmp/llama_vis_a.png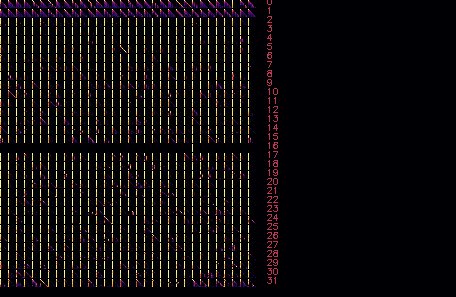
Saving tensors
--save NAME PATH — save any tensor to a file
./mia -m llama2.gguf --prompt "5 6 7 to 7 6 5, 2 3 4 to 4 " -n 3 --save l_out-14 ~/tmp/l_out-14-2Loading (patching) tensors
Activation patching is useful for analyzig connections between components of a transformer. For example, see "How to Think About Activation Patching".
--patch NAME PATH PATCH_FROM_IDX PATCH_TO_IDX — patch model’s tensor NAME for a specific token index, with values from the file PATH. Number of tokens in loaded tensor might be different from current number of tokens.
--patch-avg NAME PATH1 PATH2 PATCH_FROM_IDX PATCH_TO_IDX — same as previous, but values are loaded from two files and averaged. Two input tensors must have the same dimensions.