Oct 2023 Tweet
Bird-eye view visualization of LLM activations
I’m starting to learn about mechanistic interpretability, and I’m seeing lots of great visualizations of transformer internals, but somehow I’ve never seen the whole large model’s internal state shown at once, on one image.
So I made this visualization, for Llama-2-7B. Attention matrices are on the left, in 32 rows for 32 blocks, top to bottom. To the right, there are 64 rows: residual stream (odd rows) and internal MLP activations (even rows). Finally, output MLP and unembedding layer are on the bottom.
Activation maps are downscaled horizontally, with maxpooling, to fit into 1000px wide image.
Example for a prompt “2+2=”:
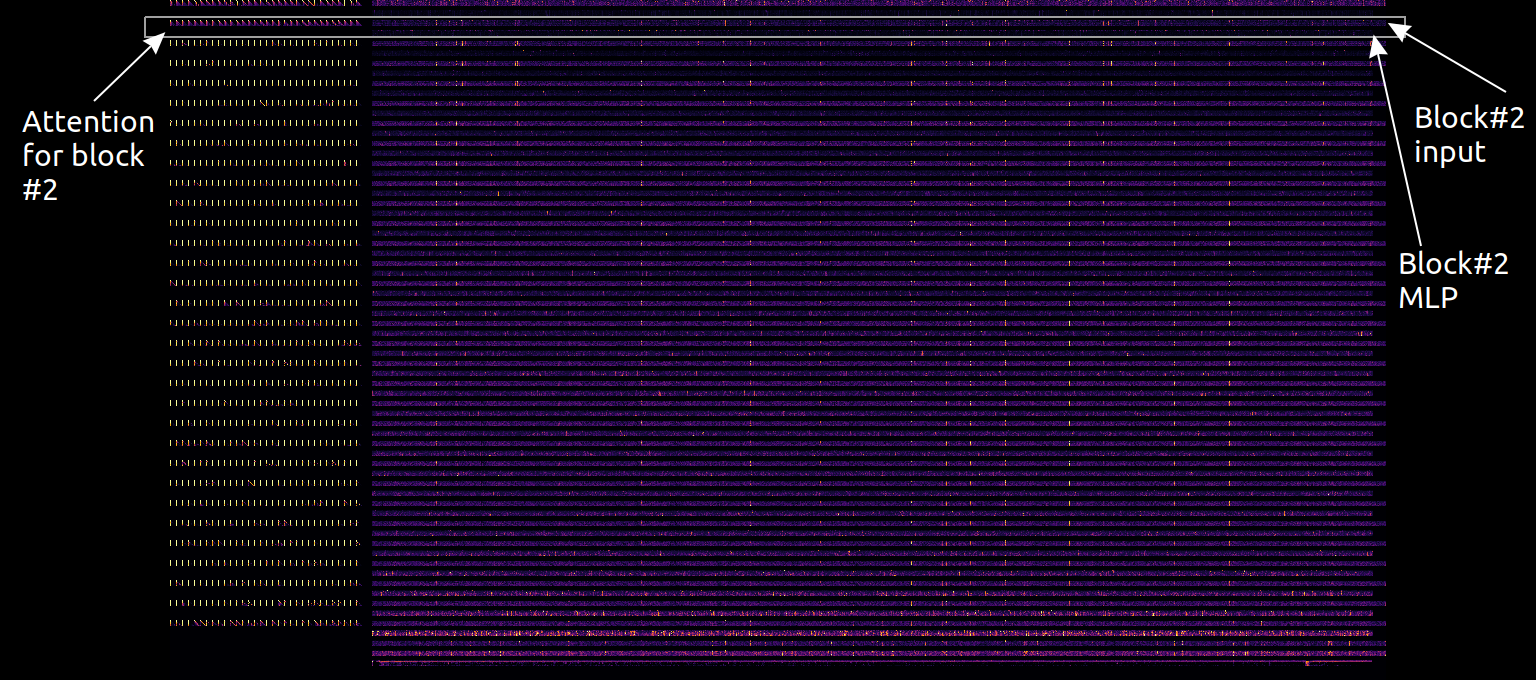
And an example for the prompt: "William Shakespeare was born in the year”:

And for the prompt "blue pencils fly over moonlit toasters”:
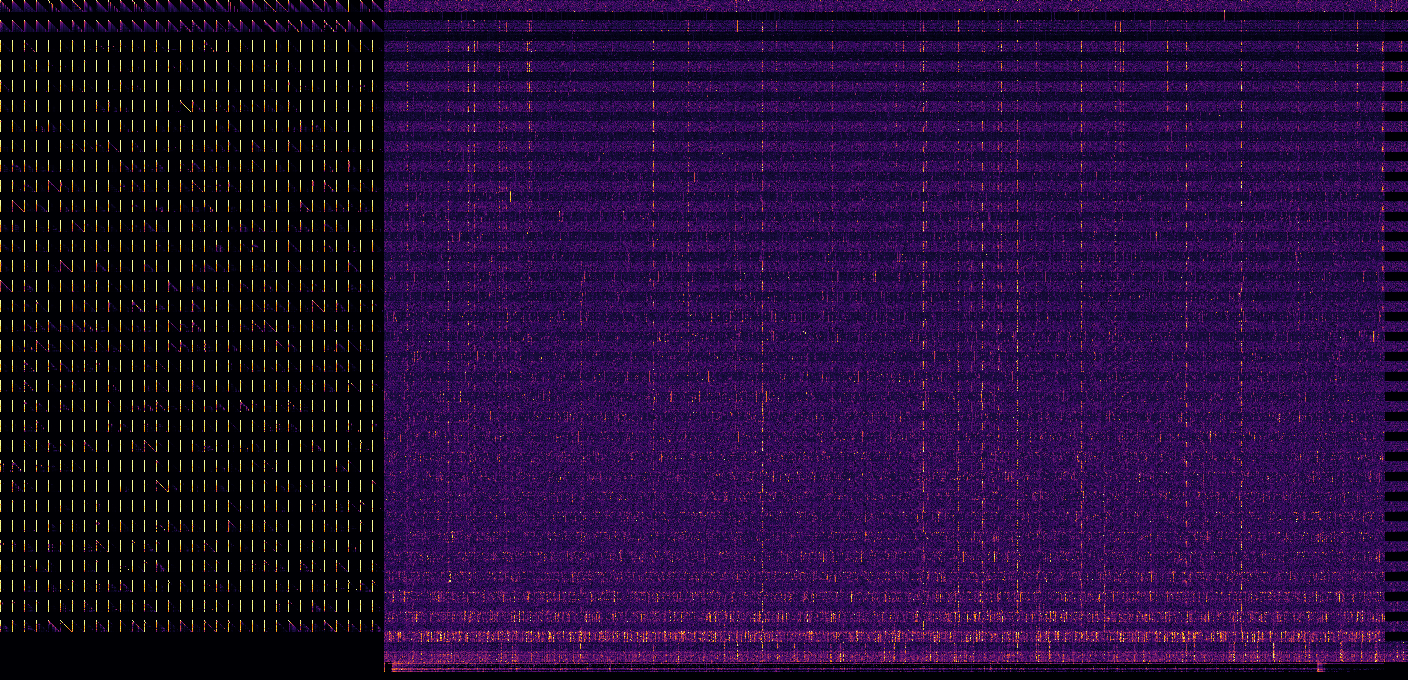
Probably not especially useful for interpretability, but at least it looks pretty )